
ビッグデータ時代、膨大なデータをどのように処理するのか?その代表的な解析方法を、グラフ処理といいます。岩渕さんは、動的な超大規模なグラフデータを格納・保存するだけでなく、その高速解析の方法を研究しています。一瞬に膨大な量のデータが流れ込む異常事態でも、リアルタイムなデータの解析を可能にする研究成果を紹介しましょう。
リアルタイムに膨大なデータを解析する~ビッグデータ時代の超大規模グラフ処理
ビッグデータ時代、膨大な量のデータを処理する典型的な問題の1つが、大規模グラフ処理というものです。グラフ処理とは何でしょう。

グラフとは頂点と辺を組み合わせることで、ものごとの連携関係を表現したものです。これによって世の中のいろいろなことが表せるようになります。

具体的に例えば、ウエブページとそのリンクは、50億頂点と1000億辺を持ち、SNSでは14億頂点・4000億辺、脳科学では1000億頂点・100兆辺を持ちます。こうした膨大なデータを劇的に迅速に処理する必要があります。

私はこの超大規模なグラフをリアルタイムで解析する方法を研究しています。そのためには、もちろん具体的な解析のアルゴリズムを考えることも重要ですが、一方で、このグラフのデータをスパコンのような大規模なシステム上で、どのように保持・格納するのか、さらにそのデータをどのように解析側のアルゴリズムに提供するのかということが、重要になってきています。これは、常時膨大な量の本の搬入を行いながら、同時に膨大な量の利用申請に対応できる図書館を設計するようなイメージです。現在私は、その実現に向けてアメリカのシリコンバレーの研究所と共同研究を行っています。
高速なリアルタイム解析を可能にするには、データを単純に到着順に格納するのではなく、どのようにデータが利用されるのかを想定することで、要求があったデータを素早く見つけることができます(例えば、図書館では同じ作者の本は同時に利用される可能性が高いため同じ場所に配置するなど)。また、大規模システムは、1つの大きなコンピュータに見えますが、内部ではたくさんコンピュータがネットワークを通してつながっています。それぞれのコンピュータ同士で通信を行う必要がありますが、その通信を各コンピュータがそれぞれのタイミングで自由に行えるようにすることで高い性能が得られています。

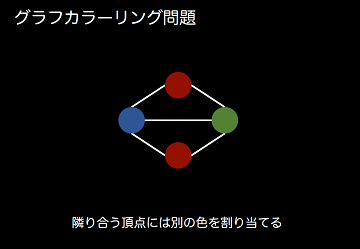
その結果の1つとして、「グラフカラーリング問題」というのを紹介します。グラフカラーリング問題とは、隣接する頂点の間では別々の色を割り当てるというものです。
それをリアルタイムで行うので、新しい「辺」が入るたびに、色の状況もアップデートされます。今回、1280億辺を持つ全ウエブページのグラフに対して実験を行いました。我々が知る限りでは、過去にこれほどのサイズのグラフに対してこの計算を行った研究はありません。256台のコンピュータを使い、1.5億辺/秒新たに挿入されても、リアルタイムでカラーリングできることを確認しました。
この1.5億辺/秒がどれくらいすごい数字なのか。少し強引な比較なのですが、ツイッターのツイート数世界記録で有名なバルス祭りの時と比較するとわかりやすいと思います。バルス祭りの時の状況を今回の実験と同じ条件で考えると約5600万辺/秒を記録しました。

これに対して今回の実験結果、1.5億辺/秒はその約3倍です。つまり我々のシステムを使うと、そのような状況でも、システムがダウンすることなくリアルタイムで解析できると言えます。


絵でわかるスーパーコンピュータ
姫野龍太郎(講談社)
スーパーコンピュータって何なのか、どのように使われているのかについて、この分野の権威である姫野先生が解説。スーパーコンピュータとは何かについて知りたい人にオススメです。

Newton 天気予報の科学(2014年6月号)
(ニュートンプレス)
スーパーコンピュータが天気予報でどのように使われているのかについて知ることができます。天気予報ってどのように行われているのか興味がある人にオススメです。